HDFS 설정하기
- Development/Hadoop, NoSQL, BigData
- 2008. 7. 25.
기본적으로는,
아래 posting과 같이 Michael G. Noll씨가 설명한 바와 같이 따라하면,
하나의 machine에 single cluster를 이상없이 설치할 수 있다.
Michael이 권고하기를,
여러 개로 multi cluster를 구축하기에 앞서, 단일 cluster로 정상 작동하는지
확인 후, 여러 개를 붙여가는 방법이 보다 효과적이라고 한다.
두 개의 cluster를 master-slave로 구성하고자 한다면,
앞서 마친 단일 cluster 2개 중 하나를 master로 다른 하나를 slave로
설정한다.
1. master와 slave의 conf/hadoop-site.xml에서 localhost 부분을 master로 바꿔준다.
2. master의 conf/masters 파일에 master를 넣는다. (slave에서는 안해줘도 됨)
3. master의 conf/slaves에 master, slave를 넣는다. (slave에서는 안해줘도 됨)
4. 앞서 single cluster 설정시에 사용했던 file system directory를 지워준다.
(... /dir/dfs)
5. master에서 namenode를 포맷한다. (bin/hadoop/ namenode -format)
6. master에서 bin/start-dfs.sh를 실행시켜 프로세스의 정상 가동 여부를 확인한다.
1) master에서 뜨는 process : Namenode, DataNode, SecondaryNamenode
2) slave에서 뜨는 process : DataNode
7. master 및 slave에서 각각 로그내 이상유무를 확인한다. (ERROR 유무)
8. master에서 MapReduce 를 실행 시킨다.(bin/start-mapred.sh)
9. jps로 프로세스를 확인한다.
1) master에 추가되는 process : TaskTracker, JobTracker
2) slave에 추가되는 process : TaskTracker
10. master 및 slave에서 각각 로그내 이상유무를 확인한다. (ERROR 유무)
정상적으로 동작한다면, start-all.sh stop-all.sh 을 실행시킴으로써
dfs 및 mapreducer를 일괄적으로 시작/종료시킬 수 있다.
요약하면, master/slave의 dfs가 정상적으로 연동되고 있다면 외형적으로는
다음 두 조건을 만족시켜야 한다.
1. master 및 slave에서 각각 떠야할 프로세스들이 jps로 확인된다.
2. master 및 slave의 각 로그파일에 에러가 없다.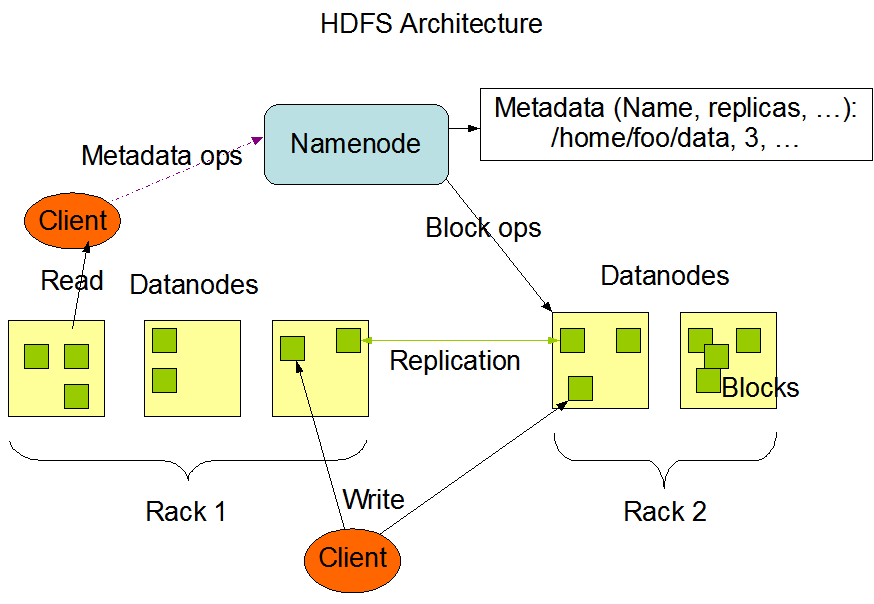
(출처 : http://hadoop.apache.org/core/docs/current/hdfs_design.html)
아래 posting과 같이 Michael G. Noll씨가 설명한 바와 같이 따라하면,
하나의 machine에 single cluster를 이상없이 설치할 수 있다.
Michael이 권고하기를,
여러 개로 multi cluster를 구축하기에 앞서, 단일 cluster로 정상 작동하는지
확인 후, 여러 개를 붙여가는 방법이 보다 효과적이라고 한다.
두 개의 cluster를 master-slave로 구성하고자 한다면,
앞서 마친 단일 cluster 2개 중 하나를 master로 다른 하나를 slave로
설정한다.
1. master와 slave의 conf/hadoop-site.xml에서 localhost 부분을 master로 바꿔준다.
2. master의 conf/masters 파일에 master를 넣는다. (slave에서는 안해줘도 됨)
3. master의 conf/slaves에 master, slave를 넣는다. (slave에서는 안해줘도 됨)
4. 앞서 single cluster 설정시에 사용했던 file system directory를 지워준다.
(... /dir/dfs)
5. master에서 namenode를 포맷한다. (bin/hadoop/ namenode -format)
6. master에서 bin/start-dfs.sh를 실행시켜 프로세스의 정상 가동 여부를 확인한다.
1) master에서 뜨는 process : Namenode, DataNode, SecondaryNamenode
2) slave에서 뜨는 process : DataNode
7. master 및 slave에서 각각 로그내 이상유무를 확인한다. (ERROR 유무)
8. master에서 MapReduce 를 실행 시킨다.(bin/start-mapred.sh)
9. jps로 프로세스를 확인한다.
1) master에 추가되는 process : TaskTracker, JobTracker
2) slave에 추가되는 process : TaskTracker
10. master 및 slave에서 각각 로그내 이상유무를 확인한다. (ERROR 유무)
정상적으로 동작한다면, start-all.sh stop-all.sh 을 실행시킴으로써
dfs 및 mapreducer를 일괄적으로 시작/종료시킬 수 있다.
요약하면, master/slave의 dfs가 정상적으로 연동되고 있다면 외형적으로는
다음 두 조건을 만족시켜야 한다.
1. master 및 slave에서 각각 떠야할 프로세스들이 jps로 확인된다.
2. master 및 slave의 각 로그파일에 에러가 없다.
(출처 : http://hadoop.apache.org/core/docs/current/hdfs_design.html)
'Development > Hadoop, NoSQL, BigData' 카테고리의 다른 글
| Docker기반 Spark Cluster 설치하기 (6) | 2020.12.15 |
|---|---|
| Local AirFlow 설치하기 (0) | 2020.12.09 |
| brew로 local zeppelin 설치하기 (0) | 2020.11.30 |
| The Hadoop Distributed File System : Architecture and Design 요약 (0) | 2008.07.29 |
| HBase에서 HQL 사용하기 (0) | 2008.07.25 |
| HBase 설치/설정하기 (0) | 2008.07.25 |
| Hadoop Installation on Ubuntu Linux 7.10 (0) | 2008.07.17 |
| HBase Installation (Standalone mode/local file system) (0) | 2008.07.15 |